Performance constraints
The scheduling mechanisms must be general, subject to the constraint
that scheduling operations are of low time complexity: O(1) in the number
of tasks and producers. The system must be scalable, high-performance,
and tolerate any single component failure. Failure of compute producers
must be transparent to the progress of the computation. Recovering from
a failed server must require no human intervention and complete in a few
seconds. After a server failure, restoring the system's ability to tolerate
another server failure requires no human intervention, and completes in
around one minute.
Basic Entities
Consumer (C): a process seeking computing resources.
Producer(P): a process offering computing resources.
It is wrapped in a screensaver or Unix daemon, depending on its hosting
operating system.
Task Server (S): a process that coordinates task distribution
among a set of producers. Servers decouple communication: consumers and
producers do not need to know each other or be active at the same time.

Figure 1: The "uses service" relation among Producers,
Consumers, TaskServers and the ProductionNetwork service.
Producer Network (N): A robust network of task servers
and their associated producers, which negotiates as a single entity with
consumers. Networks solve the dynamic discovery problem between active
consumers and available producers. Task servers and production networks
are Jini services. Fig.1 illustrates the "uses service" relationship among
these Jini services and clients. Technological trends imply that network
computation must decompose into tasks of sufficient computational complexity
to hide communication latency: CX thus is not suitable for computations
with short-latency feedback loops. Also, we must avoid human operations
(e.g., a system requiring a human to restart a crashed server). They are
too slow, too expensive, and unreliable.
Why use Java?
Because computation time is becoming less expensive and labor is becoming
more expensive, it makes sense to use a virtual machine (VM). Each computational
"cell" in the global computer speaks the same language. One might argue
that increased complexity associated with generating and distributing binaries
for each machine type and OS is an up-front, one-time cost, whereas the
increased runtime of a virtual machine is for the entire computation, every
time it executes. JITs tend to negate this argument. For some applications,
machine and OS dependent binaries make sense. The cost derivatives (human
vs. computation) suggest that the percentage of such applications is declining
with time. Of the possible VMs, it also makes sense to leverage the industrial
strength Java VM and its just-in-time (JIT) compiler technology, which
continues to improve. The increase in programmer productivity from Java
technology justifies its use. Finally, many programmers like to program
in Java, a feature that should be elevated to the set of fundamental considerations,
given the economics of software development.
There are a few relevant design principles that we adhere to. The first
principle concerns scalability: System components consume resources (e.g.,
bandwidth and memory) at a rate that must be independent of the number
of system components, consumers, jobs, and tasks. Any component that violates
this principle will become a bottleneck when the number of components gets
sufficiently large. Secondly, prefetch tasks in order to hide communication
latency. This implies multithreaded Producers and TaskServers. Finally,
batch objects to be communicated, when possible. There also is a requirement
that is needed to achieve high performance. To focus producers on job completion,
producer networks must complete their consumer's job before becoming "free
agents" again. The design of the computational part of the system is brie
elaborated in two steps:
1) the isolated cluster: a task server with its associated producers,
and
2) a producer network (of clusters). The producer network is
used to make the design scale and be fault tolerant.
The isolated cluster
An isolated cluster (See Fig. 2) supports the dag-structured task graph
model of computation, and tolerates producer failure, both node and link.
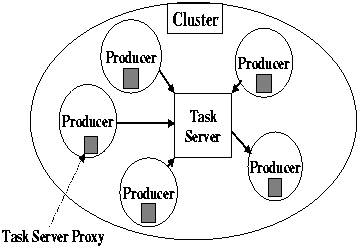
Figure 2: A Task server and its associated set of
Producers.
A consumer starts a computation by putting the "root" task of its computation
into a task server. When a producer registers with a server, it downloads
the server's proxy. The main proxy method repeatedly gets a task, computes
it, and, when successfully completed, removes the task from the server.
Since the task is not removed from the server until completion notification
is given, transactions are unnecessary: A task is reassigned until some
producer successfully completes it. When a
producer computes a task, it either creates subtasks (or a final result)
and puts them into the server, and/or computes
arguments needed by successor subtasks. Putting intermediate results
into the server forms a checkpoint that occurs as a
natural byproduct of the computation's decomposition into subtasks.
Application logic thus is cleanly separated from fault tolerance logic.
Once the consumer deposits the root task into the server, it can deactivate/fail
until it retrieves the final result. Fault tolerance of a task server derives
from their replication provided in the network, discussed below. We now
discuss task caching. Its increases performance by hiding communication
latency between producers and their server. Each producer's server proxy
has a task cache. Besides caching tasks, proxies copy forward arguments
and tasks to the server, which maintains a list of task lists: Each task
list contains tasks that have been assigned the same number of times. Tasks
are ordered by dag level within each task list. When the number of tasks
in a proxy's task cache falls below a watermark, it prefetches a copy of
a task[s] from the server. For each task, the server maintains the names
of the producers whose proxies have a copy of the task. A prefetch request
returns the task with the lowest level (i.e., is earliest in the task dag)
among those that have been assigned the fewest times. After the task is
complete, the proxy notifies the server which removes the task from its
task list and all proxy caches containing it. Although the task graph can
be a dag, the spawn graph (task creation hierarchy), is a tree. Hence,
there is a unique path the root task to any subtask. This path is the basis
of a unique task identifier. Using this identifier, the server discards
duplicate tasks. Duplicate computed arguments also are discarded. The server,
in concert with its proxies, balances the task load among its producers:
A task may be concurrently assigned to many producers (particularly at
the end of a computation, when there are fewer tasks than producers). This
reduces completion time, in the presence of aggressive task prefetching:
Producers should not be idle while other possibly slower producers,
have tasks in their cache. Via prefetching, when producers deplete
their task cache, they "steal" tasks spawned by other producers. Each producer
thus is kept supplied with tasks, regardless of differences in producer
computation rates. Our design goal: producers experience no communication
delay when they get tasks; there always is a cached copy of a task waiting
for them (Exception: the producer just completed the last task).
The producer network of clusters
The server can service only a bounded number of producers before becoming
a bottleneck.
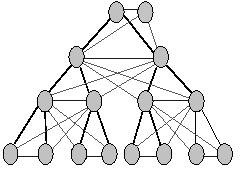
Figure 3: A fat AVL tree.
Producer networks break this bottleneck. Each server (and proxy) retains
the functionality of the isolated cluster. Additionally, servers balance
the task load "concentration" among themselves via a diffusion process:
Each server "pings" its immediate neighbors, conveying its task state.
The neighbor server returns tasks or a task request, based on its own task
state relative to the state of the pinging server. Tasks that are not ready
for execution do not move via this diffusion process. Similarly, a task
that has been downloaded from some server, no longer moves to other servers.
However, other proxies for the server can download it. This policy facilitates
task removal, upon completion. Task diffusion among servers is a \background"
prefetch process: It is transparent to their proxies. One design goal:
proxies endure no communication delays from their server beyond the basic
request/receive latency: Each server has tasks for its proxies, provided
there are more tasks in the system than servers.
We now impose a special topology, that tolerates a sequence of server
failures. Servers should have the same MTBF as mission-critical commercial
web servers. However, even these are not available 100% of the time. We
want computation to progress without recomputation in the presence of a
sequence of single server failures. To tolerate a server failure, its state
(tasks and shared variables) must be recoverable. This information could
be recovered from a transaction log (i.e., logging transactions against
the object store, for example, using a persistent implementation of JavaSpaces).
It also could be recovered if it is replicated on other servers. The first
case suffers from a long recovery time, often requiring the human intervention.
The second option can be fully automatic and faster at the cost of increased
design complexity.
We enhance the design via replication of task state, by organizing
the server network as a fat AVL tree (see Fig. 3)
We can define such a tree operationally:
-
start with a AVL tree;
-
add edges so that each node is adjacent to its parent's siblings (of the
AVL tree);
-
add another "root" with edges to all children of the AVL tree's root.
Each server has a mirror group: its siblings in the fat AVL tree (sibling
links, not shown in Fig. 3, thus are used as well). Every state change
to a server is mirrored: An server's task state is updated if and only
if its sibling's task states are identically updated. When the task state
update transaction fails:
-
The failed node (f-node) is identified by a neighboring node (a-node)
-
The neighboring node reports the failure to the root
-
The root finds as a replacement for the failed node the last inserted node
(l-node)
-
l-node is notified to occupy the position of f-node
During this process all the computations at the involved nodes are halted,
to resume only after the new connections have been established completely
and all mirroring/topology information has been updated successfully.
Even though it's a pretty complicated process, the number of steps is fixed,
hence the complexity of automatically reconfiguring the network after a
server failure is O(1). When a new server joins a network, it is placed
similarly: The algorithm essentially is a modified version of node insertion
in a height-balanced tree. Due to space limitations, a discussion of various
network self-organizing optimizations is omitted. This design scales in
the sense that each server is connected to bounded number of servers, independent
of the total number of servers: Port consumption is bounded. The diameter
of the network (the maximum distance between any task and producer) is
less than 2 log n. Most importantly, the network repairs itself: the above
properties hold after the failure of a server. Hence, the network can recover
from a sequence of such failures.