Our math-hero Charlie draws the analogy between the locations of his strikes and the locations of water droplets from a sprinkler. Discussion Question: What assumptions are being made when we draw this analogy? Given the locations of all the droplets, we would have a very good idea where the sprinkler is located!
Now, how can we re-express this type of problem into something more mathematical, a setting in which we can use, well, numb3rs? I think you'll agree that a natural starting point would be to plot the strikes as a set of points in the xy-plane. We're looking for the "source" of the points, something like the "center." Is there a good way to measure the center of a set of points? Assuming that the points really are "randomly" distributed in some sense about the center, how closely will the center that we measure approximate the true center? Good questions!
How does this work? It relates to the so-called normal distribution, which is a way of describing how numbers are distributed. You are probably already familiar with the uniform distribution on [0,1], whether you know it or not: It is the distribution that functions like rand() in C are supposed to use. The uniform distribution has the property that numbers near the center and away from the center all have an equal chance of being picked. Graphically, this distribution looks like a horizontal line of height 1, above the interval x=0 to x=1. (Note: This picture is really describing what histograms of samples from this population would look like if you had "perfectly representative" samples of large size, scaled so that the total area is equal to 1.)
In the real world, a lot of things are not distributed uniformly. Going back to the example of heights of male UCSB students, we would be much more likely to see values near, say 5'10" than near 7'1". The way the heights are distributed would be roughly symmetric, tall near the middle, and tapering off at the ends in the famous "bell-shaped" pattern: in other words, normally distributed populations have more measurements near the center and fewer far from the center. Normal distributions can be centered anywhere; the mean or population average, which we call &mu for short, of a normal distribution is located right at the peak of the bell. Also, the "bell" can be tall and thin or shorter and wider; the "spread" of a normal distribution is measured by its standard deviation, &sigma, which is the distance from the mean to either inflection point on the "bell."
On the right-had side of this page is a cute applet to graph a normal distribution having any mean and standard deviation (which they call A and B for some bizarre reason!!) that you choose. They also have a mathematical expression (labeled "PDF") defining the equation for a normal distribution with given &mu = A and &sigma = B, but we won't worry a huge amount about that at the moment. A couple of things we do need to know about the normal distribution are that
For now, let's go back to our problem about the heights of male students. Suppose that someone has told you that their heights are normally distributed with standard deviation 2 inches. Then, as noted above, 95% of the population will be within 1.96 &sdot 2 = 3.92 inches of the mean, whatever the mean is. Formally, we would say that if you choose a male student at random, the probability that his height is within 3.92 inches of the mean is 95%, or .95. But the really useful observation is that the tail also wags the dog: If the randomly chosen student's height is within 3.92 inches of the mean, then the mean is within 3.92 inches of that student's height! I know that last sentence looks obvious, but chew on it for a minute. Go ahead. I'll wait for you. OK, so even if you know nothing about the mean, you can get information about it by choosing a male student at random and measuring his height: You are 95% confident that the average is somewhere within 3.92 inches of that student's height. Suppose that your randomly chosen student is 5'9"; you are then 95% confident that the average height of all male students is between about 5'5" and about 6'1". It will be useful to keep in mind the difference between probability and confidence. Probability is about what's going to happen with a random event, while confidence is about a non-random thing, in this case the average height of all students, that is unknown.
How do we gain more certainty about the mean height? Why, we collect more data, of course -- we increase our sample size. If you think about it for a minute, I think you'll agree that it makes sense that the bigger the sample, the closer its average is likely to be to the average of the whole population - for example, it's perfectly possible to choose a student randomly who is 6'6", but it's practically impossible to choose 100 students at random and have their average height be 6'6"! The question is "How much more certainty do we gain?" Let's denote the mean of a sample by x, as opposed to the mean &mu of the whole population. Now, let's imagine the process of taking a bunch of random samples with a specific number of students, say n, in each sample, and measuring their means. These are random numbers, just as the heights of randomly chosen male students are, but what are the characteristics of these sample means? More fun facts:
./uniform_sample -n 2 -k 1000which says to make 1000 samples of size 2 and to take the sample mean from each. Then I made a histogram using a histogramming program and gnuplot, but you can use this nifty web page. It looked like this:
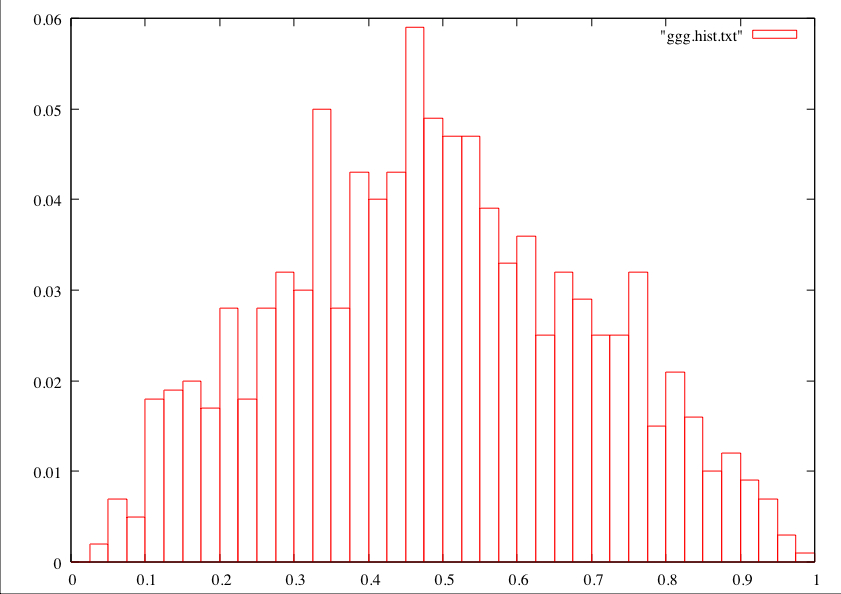
I think you'll agree that this is peaked in the middle, yet it doesn't really have a "bell shape" like the above picture of an ideal normal distribution. Now, if I do it with 1000 samples of size 20, here's what a histogram of the sample means looks like.
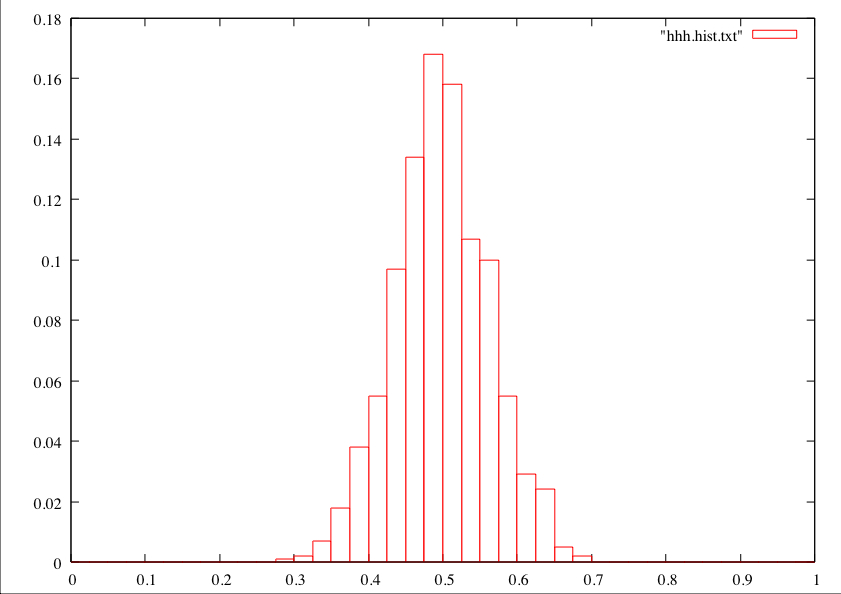
This example bears out both of my above points. First, the "spread" got a lot smaller when more values were averaged to create sample means. Second, the shape got more like a normal distribution, with the characteristic inflection point. In general, if you are using a sample to estimate a population mean, your sample size is at least 30 or so, and there's not some obvious weirdness to the way the data looks (multiple "clumps" or wild asymmetry), you can basically just assume that you started with a normal distribution, because the sample mean distribution is going to be "normal enough" anyway.
The next issue is that in general you don't know the standard deviation of a population ahead of time. The natural thing would be to say, "Since I don't know the standard deviation of the whole population, I will use the best estimate I have for it, namely the standard deviation of my little sample." In fact, that almost works, as we'll see shortly. For now, let's imagine that it does, and we'll attack the problem of determining the mean height of male UCSB students based on some actual numbers.
Accordingly, suppose we take a sample of 14 UCSB students at random (the
"random" part is actually tricky, by the way; how would you
make sure your sample was random??), and we measure their heights, in inches, to be 70.0, 69.7,
67.3, 69.1, 65.8, 70.7, 69.5, 68.5, 67.0, 70.7, 72.1, 69.9 66.3, and
69.3. The sample mean x comes out to almost exactly 69 inches; if only
we knew the standard deviation of the population, we could pull a
trick like the one we did above and state some stuff confidently. So
let's estimate it with the sample standard deviation, which we
denote by s. Recall from above that standard deviation
is a measure of how "spread out" the data tend to be away from the mean.
To find s, then, take each measurement, subtract the mean, and square
the difference. (Among other things, squaring makes sure that all distance,
above or below, counts positively, which is good,
right? We don't want large positive and negative differences canceling out if
we want to measure how spread out the data are.) We then add up these
squares, divide by one less than the number of data points, and
take the square root. (I know, I know, it would make a lot more sense
to divide by the number of data points, so you were just averaging.
There's actually some controversy in the world of statistics which
number you should use to divide by when you calculate the thing called
the "sample standard deviation;" the reason I made the choice I did
will be spelled out in the next section.) If you like things in
formulas, well, here you go:
s2 = (&sum (xi − x)2)⁄(n − 1),
where the subscript "i" is used as a label for the data points (so
x1 = 70.0, x2 = 69.7, etc.),
&sum means to add 'em all up, and n is the number of things in your
sample. (s2 is called the "sample variance," which it turns out
will come in handy as well.) Now take the square root of
that to find s. I got s &asymp &radic42⁄13 &asymp 1.80 when I did
this. So if we decide
that the sample standard deviation 1.80 is a good estimate for the
true population standard deviation, then we can assert with 95%
confidence that the true population mean is somewhere in the range 69.0
plus or minus our magic number 1.96 times 1.80⁄&radic14, which is about
69.0 ± .94. Thus we are 95% confident that the mean
height for UCSB male students is between about 68.06 and 69.94 inches.
Finally: the right height! OK, now let's at long last
work out the correct answer to the problem of determining, with 95%
confidence, the mean
height of a male UCSB student based on our random sample of 14
students. We first calculate
s &asymp &radic42⁄13 &asymp 1.80,
divide by the square root of the sample size to get 1.80⁄&radic14 &asymp 0.48
and then look in the row of the t-table for 13 degrees of
freedom. For 95% confidence, we use the 0.025 column (aren't
you glad you spent that time way back when acquainting yourself with
the normal table??), which gives 2.160; so we are in fact 95%
confident that the mean height for all male UCSB students is somewhere
in the range
69.0 ± 2.160 &sdot 0.48 &asymp 69.0 ± 1.03 =
[67.97,70.03].
This range is called a 95% confidence interval for the mean. Observe that it's a little wider than the "almost correct" one we produced back before we met Student. (Based on the formulas used, can you spot the reason why it's wider?) The notion of confidence is a very useful one in statistics, so make sure you understand what this statement says.
Discussion Question: Imagine a 90% confidence interval for the mean, based on the same info. Would it be wider or narrower? Why? Exercise: Go ahead and calculate that 90% confidence interval, and use your answer to check your response to the above Discussion Question. Make sure you can answer the "Why?" part, even if you got it wrong the first time! (Answer: About [68.15,69.85].)
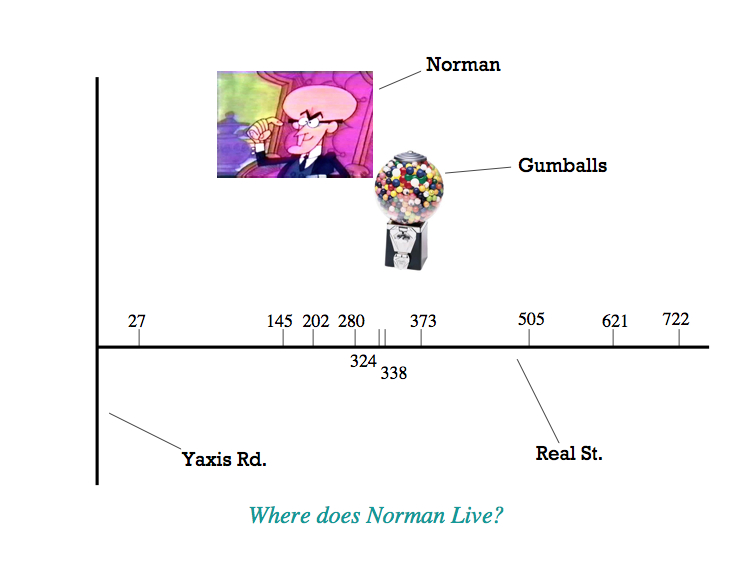
Problem: "Normal Norman" is the FBI's nickname for a bubble-gum thief who operates entirely on Real Street, a long straight street whose addresses measure the distance, in hundredths of miles, from the point where the street dead-ends into Yaxis Road. We know from a large database of serial bubble-gum thieves that they tend to strike in a pattern that is normally distributed about their home. There have been thefts fitting Norman's pattern near the following addresses along Real Street: 27, 145, 202, 280, 324, 338, 373, 505, 621, and 722. The FBI wants you to find a 90% "hot zone" for Norman's residence; in other words, they want you to come up with a range of addresses within which you're "90% sure" that Norman lives. Can you find the desired "hot zone" and thus help them end this crime spree?
First, let's define a bivariate distribution: Imagine taking data that comes in ordered pairs; they could, for example, be (height, length of left arm) for American adult females, or they could be (x-coordinate, y-coordinate) for, oh, I don't know, a series of heinous crimes committed in Los Angeles (relative to a coordinate system of our choosing). The x and y variables could be independent, meaning roughly that knowing the value of one of the variables gives you no information about the values that the other variable might have, or they might not be. In the first example of this paragraph, height and shoe size are surely not independent, since taller people, for the most part, tend to have longer arms. Note that independence is not about guarantees, just about the distibution that one variable has once you fix a value of the other variable. Now, a bivariate normal distribution is defined in terms of formulas, which I don't want to worry about too much for this course, but you can kind of spot them if you know what you're looking for, so let's start with an example or two.
Suppose that we took a good darts player, told her to aim at the bull's-eye, and recorded the spots she hit over a large number of throws as (x,y) coordinates measured with the bull's-eye as the origin. The "center" of her tosses would probably be very near the origin. We might also assume that her errors in the x- and y- directions are more or less independent: for instance, knowing that she was 2 inches too far to the right gives you no information about her vertical error. We might also assume that her errors in the vertical direction are generally the same size as her errors in the horizontal direction. If we plot all of these points, we may get something that looks a little like
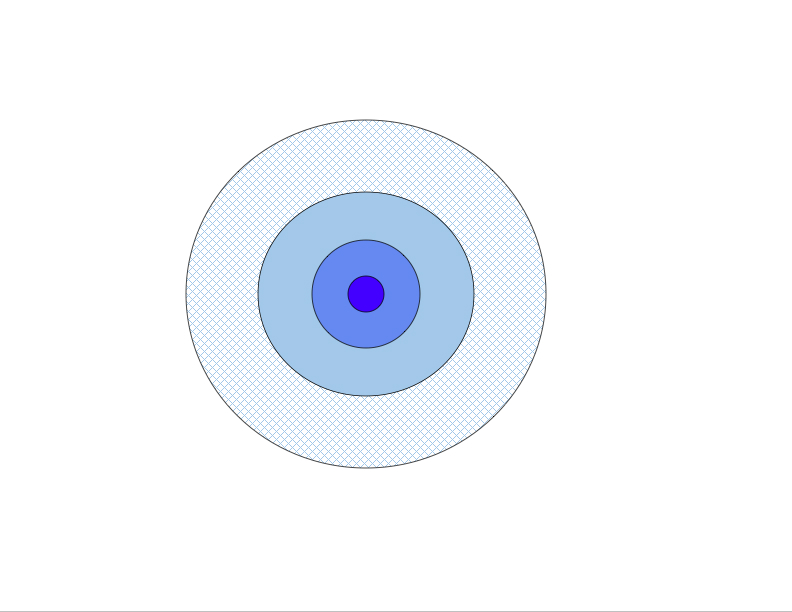
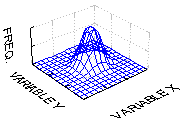
this, where darker regions correspond to a higher density of outcomes. Notice that the data points are concentrated toward the center, just as in our friend the single-variable normal distribution, and in this case, the distribution of y-values is independent of the x-value chosen, and vice versa. The gadget corresponding the the "bell curve" in one variable would actually be 3-D and look a bit like the figure below.
Now, in the "tail wagging the dog" spirit of the earlier discussion, imagine that you see the pattern of points but don't know where the bull's-eye is, and you want to come up with some region where you're 95% confident that the bull's-eye must live -- a 95% confidence region, if you will. The most natural shape you'd hope for would be a circle, provided we still are assuming that the x- and y- errors are independent and similar in size. (I should note that the variables might be independent and yet the pattern might not be circular; for example, if the dart thrower's vertical error was in general twice as large as her horizontal error, each circle in the figure would become an ellipse with long axis vertical and short axis horizontal. The issue of circles vs. ellipses for independent data is really just one of scaling -- choose appropriate (possibly different) units for the two variables, and it'll come out circular.)
On the other hand, what if x and y aren't independent? A good example is seen here, where SAT scores are plotted vs. ACT scores and each point stands for an individual student.
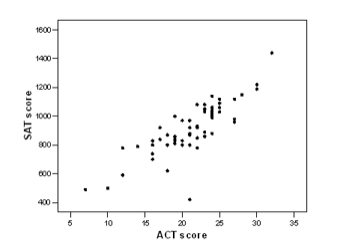
Briefly, then, one of its salient features is that both variables are normally distributed on their own, and furthermore, if you set one variable equal to a fixed number, the possible outcomes for the other variable are normally distributed, no matter what fixed value you use. As noted above, the particular normal distribution may depend on the fixed value. For instance, the (height, arm length) pairs discussed above would likely have a distribution that is fairly close to a bivariate normal. The mean arm length would go up as the height went up, and vice versa. The next question is how to find the circles or ellipses coming from a bivariate normal distribution. With one variable, all we needed to deal with were the mean x and the standard deviation s from our sample. With a bivariate normal, we have an analogous mean (x, y), but this time instead of just a standard deviation, we need to describe the spread of both variables and also how the location of one variable affects the location of the other. Miraculously enough, this is all encoded neatly in the variance-covariance matrix for the two variables. Here's how it works: If you have a sample of n points, the covariance between x and y is calculated as
| Cov(x,x) | Cov(x,y) |
| Cov(y,x) | Cov(y,y) |
| sx2 | Cov(x,y) |
| Cov(x,y) | sy2 |
| &sigmax2 | Cov(X,Y) |
| Cov(X,Y) | &sigmay2 |
With me so far? Up to this point, we have stored, rather conveniently but somewhat mysteriously, our variance-covariance information in a matrix. The convenience will become even more manifest, and some of the mystery melt away, yea, like a shroud of mist in the morning sun, before long. But first, we have to remember, or learn as the case may be, how to multiply matrices.
First, a little notation: We call a matrix m×n, read "m by n," if it has m rows and n columns. Note that it's easy to add two m×n matrices: just add the corresponding elements in the two matrices and get the m×n matrix of sums. Subtraction is of course similar, but multiplication is a hair trickier. For one thing, if you have two matrices A and B, you can't multiply them unless the number of columns of A is the same as the number of rows of B. So let's say that A is m×n; that means B needs to be n×k for some k, or the deal's off. If this is the case, the product AB is a new matrix, the dimensions of which are m×k, and you calculate each entry in this matrix by summing the products of the corresponding elements in the appropriate row of A and the appropriate column of B. For example, suppose that
| A = |
|
and B = |
|
Exercise: Calculate the full matrices AB and BA. (Note that often it only makes sense to multiply matrices in one order, but the dimensions of these allow us to multiply them in either order.)
Answers:
| AB = |
|
; BA = |
|
Don't even try to tell me that wasn't a good time. Now it's time for a few Fun Facts about matrices:
|
|
and |
|
|
| A = |
|
, then A−1 = |
|
Now we're going to use our newfound skills on the bivariate normal. Recall that the problem we're working on is (roughly) to figure out a region containing a desired fraction of a bivariate normal population, and that in order to solve the analogous problem in one variable we looked at how many standard deviations we needed to move from the mean. The variance-covariance matrix of the bivariate normal is going to serve a similar role to the standard deviation in one variable. In fact, we're going to use the inverse of that matrix to "undo" the effects of variance and covariance and "standardize" the variables, so that we can use a single lookup table for all bivariate normal distributions, analogous to the above one-variable normal table.
Here are the details: Call the variance-covariance matrix &Sigma. (I apologize for the apparent double use of the symbol, but both are absolutely standard! In fact, it will generally be very clear from the context whether I mean "variance-covariance matrix" or "sum." Also, they are in fact distinct characters: The variance-covariance matrix symbol (&Sigma) actually looks smaller than the sum symbol (&sum).) Then an equation of the form
|
&sdot &Sigma−1 ⋅ |
|
= constant |
OK, let's do an example. Suppose that we have a bivariate normal distribution with &mux = 3, &muy = 2, and variance-covariance matrix
| Σ = |
|
|
|
|
= 5. |
|
|
= 5. |
Exercise: Back in the dart example, we postulated that our thrower's horizontal errors x and vertical errors y are independent of one another, meaning that their covariance is 0, and that the variances of x and y are equal. Show that the variance-covariance matrix is a multiple of I2 and that, regardless of the chosen constant on the right-hand side, the matrix equation gives a circle.
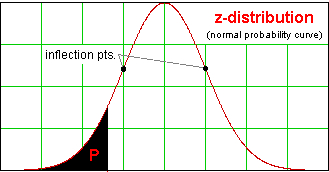
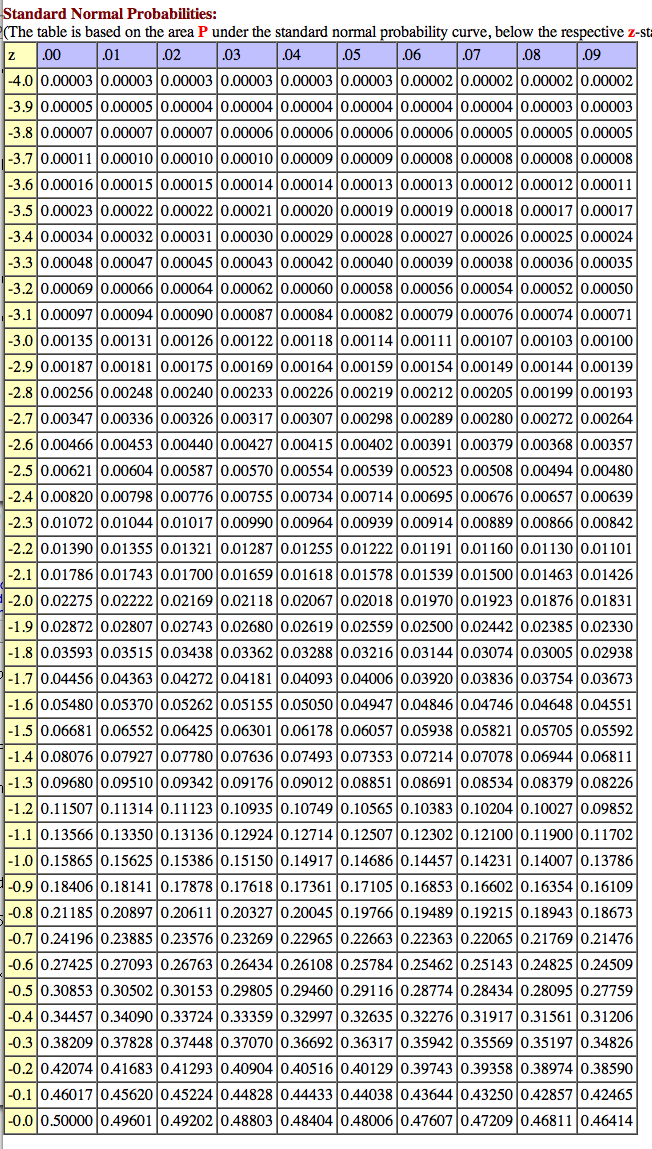
Of course, the constant on the right-hand side of our matrix equation tells us what proportion of the population lies inside the resulting ellipse. As I hinted at above, there is a single table of values that we can use to answer that question regardless of the specifics of the given bivariate normal distribution; the values in the table come from a &chi22, read as chi-squared with two degrees of freedom, distribution. Here's that table, together with directions. To be honest, the only thing I have ever seen done with a &chi2 involves the "right tail," illustrated in the left-hand sketch below, and I find it a little weird that they'd even put in the left-hand extreme probabilities, but hey, they're the pros.
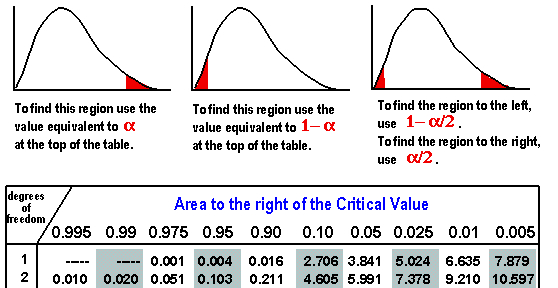
As an example of how to use this table, the constant value 5
we used above generated an ellipse that contains between 90% and 95%
of the entire population, since 90% are within the ellipse you get
from using the constant 4.605 and 95% are within the ellipse coming from
constant value 5.991. (Observe that we had to subtract from 1, because
this table tells you how much of the population is above the
given value, which means the part outside our ellipse!) If you
need a more precise answer, you can use the nifty calculator found
here.
I plugged in 2 for "d.f." and 5 for "c2," and it gave me a
"probability" value of 0.0821; in other words, .9179, or 91.79%, of
the population is within our ellipse with constant value 5.
Exercise:The
calculator can calculate both ways; in other words, if you need a constant
for exactly 84% of the population, it will do that for you, too. Try
it. What constant did you find? (Answer: 3.665)
| n &sdot |
|
&sdot S−1 ⋅ |
|
= constant |
For example, suppose that we've estimated our variance-covariance matrix using a sample of 23 points. Then we use 2 degrees of freedom in the numerator and 21 in the denominator. To find the appropriate constant for 90% confidence, I played around until I got "p" to equal 0.1, which I found for F = 2.5746. Then I multiplied this by 44⁄21 and got the constant value 5.3944 for 90% confidence. If I then wanted to graph this 90% confidence region, I would use the estimated variance-covariance matrix from the sample, the sample means, and the above formula with n=23, and toss all that info to our equation-plotting friend we met earlier.
A bivariate normal distribution can be defined as any distribution arising as a linear transformation of a distribution consisting of two independent standard normal variables, plus a constant vector. (Recall that standard in this context means &mu = 0 and &sigma = 1.) In other words, if U and V are independent standard normal variables, and A is a 2×2 matrix, then the matrix product [U,V]A + [&muX,&muY] results in a vector [X,Y] that has a bivariate normal distribution, and conversely, any bivariate normal distribution arises in this way. The mean of this distribution is [&muX,&muY], and we can figure out the variance-covariance matrix for X and Y from the coefficients of A, but to do that we'll need to make a few observations about how variances and covariances work.
First, if we multiply all the x-coordinates by a constant, say c, what happens to the covariance? In other words, if we know Cov(x,y), can we calculate Cov(cx,y)? Well, first off, if you multiply all the xi by c, then the average gets multiplied by c as well, so the mean of our new values is just cx. Now, let's throw that info into the above formula for covariance to get
Finally, it almost goes without saying that the covariance of anything with a constant is 0: if the xi are all equal, then they are all equal to x, and every term in the sum would involve a factor of xi − x = 0. In light of the above facts, then, the variance-covariance matrix of X and Y is the same as that of X − &muX and Y − &muY, which we can calculate as follows. If we write
| A = |
|
, then |
| = |
| &sdot A = |
|
| a2+c2 | ab+cd |
| ab+cd | b2+d2 |
| = |
| &sdot A−1. |
This general method works for any number of
variables you like. For example, we could have done all of this in one
variable as well, and the answers would have come out just the same as
they did in the first part of this lesson when we were dealing with
single-varaible normal distributions. Let's check that claim: In one
variable (start out with known σ), the variance-covariance
matrix has only one entry, namely &sigma2, and the equation
for the boundary of our confidence region becomes simply (x−&mu)
&sdot (&sigma2)−1 &sdot
(x−&mu) = const, or (x−&mu)/&sigma = ±
√const, or x =
&mu ± &sigma √const. The constant here is
governed by a &chi2 distribution with one degree of
freedom, which is just the square of a standard normal distribution, hence the
square root on the constant.
Finally, here are a few details about the changes you have to make
when doing confidence
intervals, which are really just 1-dimensional confidence
regions. First off, the an F-distribution with 1 degree of
freedom in the numerator and k in the denominator, which is
what we'd use for (k + 1) one-dimensional data points, is the
square of a
{kind=link}